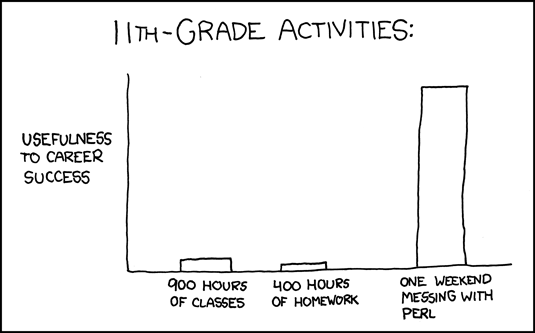
Another dose of truth from XKCD.
....the most important computer science course a CS student could ever take [...is...] Typing 101.
#ifdef CONFIG_FEATURE_X ....code for feature x.... #endif
#ifdef CONFIG_FEATURE_X
#if !defined(CONFIG_FEATURE_X_AAA) \
&& !defined(CONFIG_FEATURE_X_BBB) \
&& !defined(CONFIG_FEATURE_X_CCC)
#error If you are going to enable Feature X, you must choose one of its variants: AAA, BBB, or CCC. \
It is non-sensical to enable Feature X and not enable one of these variants.
#endif
#if (defined(CONFIG_FEATURE_X_AAA) \
&& ( defined(CONFIG_FEATURE_X_BBB \
|| defined(CONFIG_FEATURE_X_CCC))) \
|| \
\
( defined(CONFIG_FEATURE_X_BBB) \
&& ( defined(CONFIG_FEATURE_X_AAA \
|| defined(CONFIG_FEATURE_X_CCC))) \
|| \
\
( defined(CONFIG_FEATURE_X_CCC) \
&& ( defined(CONFIG_FEATURE_X_AAA \
|| defined(CONFIG_FEATURE_X_BBB)))
#error Feature X variants AAA, BBB, and CCC are all mutually incompatible!
#endif
Warning: this file is known to be mis-compiled with this version of compiler!
void do_something(const char *s)
{
char *s2 = (char *)s;
s2[0] = 'a';
}
/* This is some header file */
/* For an exact definition of this keyword, please ask $COWORKER */
#define MEANINGLESS_CONST
void do_something(MEANINGLESS_CONST char *s)
{
s[0] = 'a'; /* much more streamlined!!! */
}

Holtman and shortstop Liz Wallace lifted Tucholsky off the ground and supported her weight between them as they began a slow trip around the bases, stopping at each one so Tucholsky's left foot could secure her passage onward. Even with Tucholsky feeling the pain of what trainers subsequently came to believe was a torn ACL (she was scheduled for tests to confirm the injury on Monday), the surreal quality of perhaps the longest and most crowded home run trot in the game's history hit all three players.This is simply an awesome story, one that I will never forget.
custssh = ssh -p your-port-number -l subversion \
-i /your/home/directory/.ssh/id_your_new_KEY
command="svnserve --root=/home/subversion
--tunnel-user=your-loginid
--tunnel",no-port-forwarding,\
no-agent-forwarding,no-X11-forwarding,no-pty ssh-dsa #$#$#$#$#key-stuff-goes-here-lBB you@somedomain.org
svn co svn+custssh://SERVER/repo/trunk/top-secret-project
Did you know? By recycling glass milk bottles, Catamount Farm customers have helped save an estimated 40,000lbs of plastic over the past 6 years!
int f(int x)
{
int result;
if (x < 3)
result = 1;
else
result = 0;
return result;
}
int f(int x)
{
if (x < 3)
return 1;
return 0;
}
Hi, I'm Kevin. I've been assigned by $MANAGER to work on $FEATURE in the $BIG_SUBSYSTEM. $MANAGER tells me that I can use you as a resource for this project. I'm trying to come up to speed with $BIG_SUBSYSTEM ; I've started reading the available documentation, but could you perhaps give me an overview of $BIG_SUBSYSTEM so that I have a better idea of what is going on in this subsystem.
void f(int x)
{
LOCK(&mutex);
switch (x) {
case FOO:
if (someFunc() == ERROR) {
UNLOCK(&mutex);
return;
}
/* do something else */
}
break;
/* HERE IS MY CODE */
case BAR:
if (someFunc() == ERROR) {
UNLOCK(&mutex);
return;
}
/* do something else */
}
break;
/* ...100 more cases... */
}
UNLOCK(&mutex);
}
void f(int x)
{
LOCK(&mutex);
LOCK(&some_other_mutex);
switch (x) {
case FOO:
if (someFunc() == ERROR) {
UNLOCK(&some_other_mutex);
UNLOCK(&mutex);
return;
}
/* do something else */
}
break;
/* HERE IS MY CODE */
case BAR:
if (someFunc() == ERROR) {
UNLOCK(&mutex);
return;
}
/* do something else */
}
break;
/* ...100 more cases... */
}
UNLOCK(&some_other_mutex);
UNLOCK(&mutex);
}
void f(int x)
{
LOCK(&mutex);
LOCK(&some_other_mutex);
switch (x) {
case FOO:
if (someFunc() == ERROR) {
....
}
else {
....
}
}
break;
/* HERE IS MY CODE */
case BAR:
if (someFunc() == ERROR) {
....
}
else {
....
}
break;
/* ...100 more cases... */
}
UNLOCK(&some_other_mutex);
UNLOCK(&mutex);
}

If the packet is transmitted, it will fall into the ether;
If it remains in the queue, it will exceed its TTL,
That little VLAN tag
Is a very strange thing.
# put this in your .bashrc/.kshrc/etc.
txtfind () {
if [ $# -eq 0 ] ; then
txtfind .
else
perl -MFile::Find -e 'find(sub{ print "$File::Find::name\n" if (-f && -T); }, @ARGV);' "${@}"
fi
}
txtfind /etc | xargs grep 192.168.9.37...if, for example, I wanted to figure out why a machine was configured to use some strange IP address. This beats typing something like:
find /etc -type f -print | xargs grep 192.168.9.37...because, of course, this will likely cause grep to troll through some binary files. In the end, this might hose your terminal.
txtfind0 /usr | xargs -0 grep foo...but with this new tool, ack, I'll be able to eliminate a lot of hassle by simply typing something like:
ack --type=text foo /usrThat's not to say that things like my txtfind0 alias are now obsolete. Let's say, for example, I wanted to find a file that contained both the phrases "weapons of" and "mass destruction" -- in this case it would be as easy as:
txtfind0 /usr/secret | \But, just the same, I am enthusiastic to have a great new tool in my arsenal. Ack has a bunch of other features that I haven't really touched on here (my favorite is its intelligent ability to skip files in .svn directories) -- I encourage everybody to check ack out.
xargs -0 perl -l -0777 -ne 'print $ARGV
if (/weapons of/i && /mass destruction/i)'
#if defined(SOME_COMPILER) || defined(SOME_OTHER_COMPILER)
#pragma pack (1)
#endif
struct SomeMsgStruct {
uint32_t field1;
uint32_t field2;
....
uint64_t fieldN; /* NEW FIELD */
}
#if defined(GNUC)
__attribute__ ((__packed__))
#endif
;
#if defined(SOME_COMPILER) || defined(SOME_OTHER_COMPILER)
#pragma pack (0)
#endif
SomeMsgStruct x;
assert(sizeof(x) == (sizeof(x.field1) + sizeof(x.field2) + sizeof(x.fieldN)));
printf("sizeof SomeMsgStruct: %d\n", sizeof(SomeMsgStruct));
assert()? Oh, what's that? When I first started working with your new code this morning, I kept on getting this `assertion failed' message. But I just wanted to get the code going, so I commented out that pesky line of code.
We can't fix the problem because we can't even produce a build with the current codebase that doesn't crash instantly on the board. Something in the code changed. I've tracked it down; it is a compiler bug. We'll have to call the compiler vendor.
extern uint32_t foo(uint32_t some_param);So, at this point I directed my colleague to utilize one of my favorite debugging techniques -- I asked him to run the compiler on the source file in question, but to only run the C preprocessor on the file. This is usually as simple as invoking the compiler like "cc -E" or "gcc -E". After a few minutes of futzing around with the win32 IDE that controlled the compiler, we were eventually able to generate the preprocessed output, all dumped to a file.

{kind=link}